
Python DataSet Comparison
Python Dataset Comparison in Jupyter Notebooks
This article describes how to use Pandas in Python to compare 2 CSV files in Python using DataFrames to find matching and non-matching records. The CSV dataset files were created and downloaded from the convertcsv.com website using the Online Generate Test Data page: https://www.convertcsv.com/generate-test-data.htm. The code will import this data as DataFrames.
Load the datasets into DataFrames
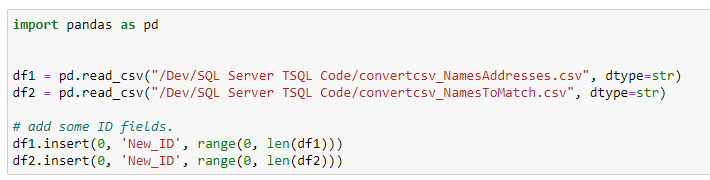
Write code to use pandas to read the Names and Address CSV data file into a DataFrame (df1) and read the Names to match CSV file into DataFrame df2. An additional unique integer ID is added to each dataframe.
Code the dataframes to drop the NaN values, if any.

Add columns for full name - Create code to add a name field to the dataframes for the concatenated First and Last Name columns and strip additional white space on the left of each.
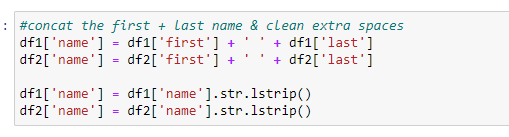
Add columns for full address field - Create code to add a combined address field to the dataframes for the concatenated address, city, state, and zip columns and strip additional white space on the left of each.

Clean up any extra spaces in the dataframe columns using Regex replace in both dataframes.

Code for Comparing DataFrames write code to match the names from dataframe df2 to the dataframe df1.
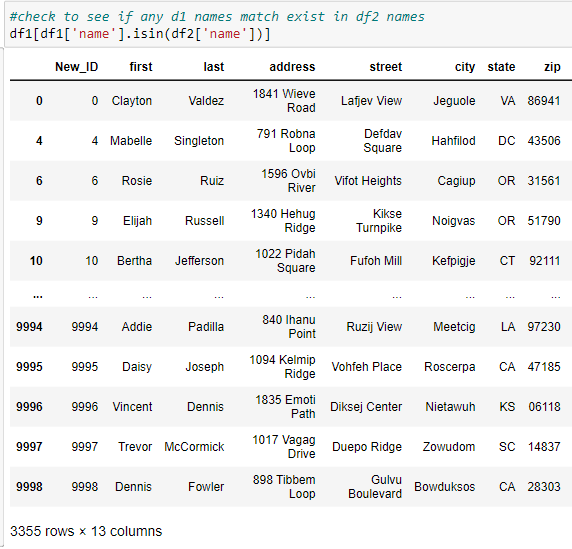
Write code to match the names of df2 to dataframe df1. In this sample, names in 3355 rows from df1 match dataframe df2.
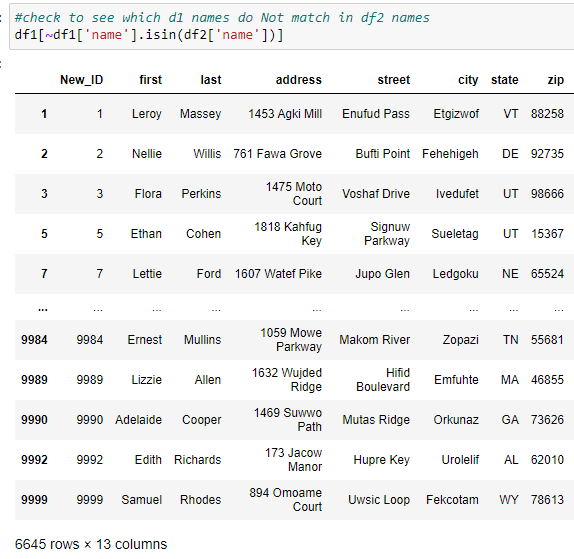
Write code to find names from dataframe df2 Not in the dataframe df1. Names in 6645 rows from df1 do not match dataframe df2.
 ------------continue with matching 4051 records and outputting tab delimited file with matches to show cartesian product
between dataframes due to matching.
-------------------------------
------------continue with matching 4051 records and outputting tab delimited file with matches to show cartesian product
between dataframes due to matching.
-------------------------------
Merge the 2 DataFrames by matching names Write code to use an inner merge of the names from dataframe df2 to the dataframe df1.

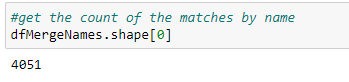
Write code to get the count of the matches by name for the 2 datasets.
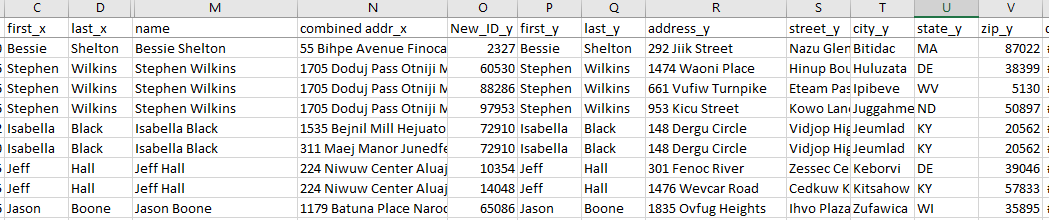
Create code to export the new merge dataframe to a file to review the matched names.

The exported data shows that some df2 names match multiple df1 names in the merged dataframe. If we are not concerned with the addresses from df1, then the duplicate names can be removed from this dataframe.
Write code to drop the duplicate matches by name for the 2 datasets.

Write code to get the count of the updated matches by name for the 2 datasets.

Create code to export the updated merge dataframe to a file to review the removed "matched" names.

Review the exported data showing that the duplicate names have been removed from the merged dataframe.
